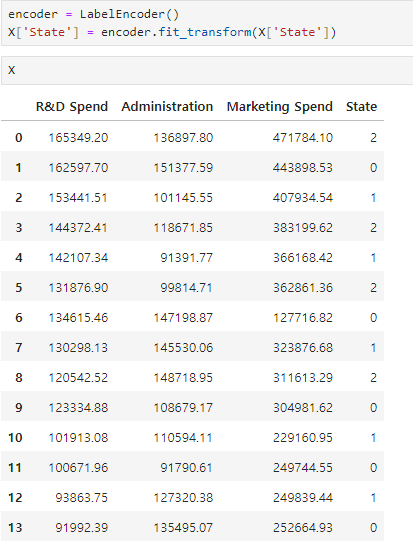
from sklearn.model_selection import train_test_split train_test_split() : 데이터셋을 학습용과 테스트용으로 나눈다. >>> X_train, X_test, y_train, y_test = train_test_split(X, y, test_size=0.2, random_state=32) >>> X_train array([[1. , 0. , 0. , 0.73913043, 0.68571429], [0. , 1. , 0. , 0.13043478, 0.17142857], [1. , 0. , 0. , 0.34782609, 0.28571429], [1. , 0. , 0. , 0.91304348, 0.88571429], [0. , 0. , 1. , 0.478260..