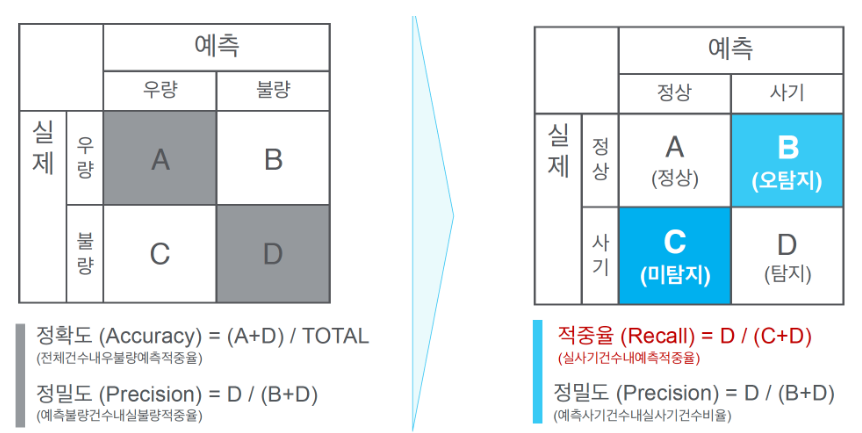
confusion_matrix(실제값, 예측값) : 실제값과 예측값을 행, 열로 셋팅해서 위와 같이 결과값 반환
from sklearn.metrics import confusion_matrix
>>> cm = confusion_matrix(y_test, y_pred)
>>> cm
array([[52, 6],
[14, 28]], dtype=int64)
# 정확도 계산 : accuracy
# (52+28) / cm.sum()
accuracy_score(실제값, 예측값) : 정확도 계산
from sklearn.metrics import accuracy_score
>>> accuracy_score(y_test, y_pred)
0.8
classification_report() :
분류 모델의 성능을 요약하는 데 사용된다.
주요 성능 지표인 정확도, 정밀도, 재현율, F1 점수를 제공한다.
from sklearn.metrics import classification_report
>>> print(classification_report(y_test, y_pred))
precision recall f1-score support
0 0.79 0.90 0.84 58
1 0.82 0.67 0.74 42
accuracy 0.80 100
macro avg 0.81 0.78 0.79 100
weighted avg 0.80 0.80 0.80 100
heatmap 사용해서 시각화
import seaborn as sb
>>> sb.heatmap(data=cm, cmap='RdPu', annot=True)
>>> plt.show()

'인공지능 > Machine Learning' 카테고리의 다른 글
| [Machine Learning] 분류 예측 Support Vector Machine (SVM) (0) | 2024.04.15 |
|---|---|
| [Machine Learning] 분류 예측 K-NN (0) | 2024.04.15 |
| [Machine Learning] 분류 예측 LogisticRegression (0) | 2024.04.15 |
| [Machine Learning] LinearRegression 인공지능, 변수 파일로 저장 joblib.dump() (0) | 2024.04.15 |
| [Machine Learning] LinearRegression 인공지능 실제 예측 (0) | 2024.04.15 |