import numpy as np
import tensorflow as tf
from tensorflow.keras.datasets import fashion_mnist
# TensorFlow keras datasets API에 들어있는 Fashion MNIST 데이터 가져와 사용
트레이닝셋과 테스트셋을 가져온다 => 텐서플로우에서 사진을 넘파이로 변환해둔 데이터
>>> (X_train, y_train), (X_test, y_test) = fashion_mnist.load_data()
>>> X_train.shape
(60000, 28, 28)
이미지 확인 : plt.imshow()
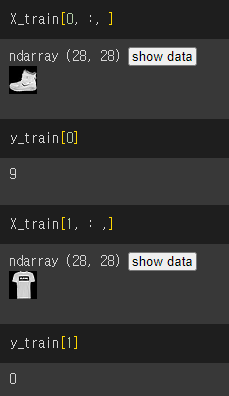
이미지는 범위(0~255)가 정해져 있기 때문에 StandardScaler, MinMaxScaler 를 쓰지 않고
범위의 최대값인 255 로 나눠 피처 스케일링 한다.
>>> X_train = X_train / 255
>>> X_test = X_test / 255
Flatten() : 배열이나 행렬의 차원을 납작하게 만드는 함수
예를 들어 2차원 배열이 있다고 가정한다면 이 배열을 flatten() 함수를 사용하여 1차원 배열로 만들면
모든 요소가 한 줄에 연이어져 있는 형태로 변환됨
from tensorflow.keras.models import Sequential
from tensorflow.keras.layers import Dense, Flatten
>>> def build_model():
model = Sequential()
model.add(Flatten())
model.add(Dense(128, 'relu'))
model.add(Dense(10, 'softmax'))
# y값이 레이블 인코딩으로 되어있으므로 sparse_categorical_crossentropy 사용
model.compile('adam', loss='sparse_categorical_crossentropy', metrics=['accuracy'])
return model
학습, 정확도 확인, 예측시켜 변수에 저장
>>> model = build_model()
>>> model.fit(X_train, y_train, epochs= 5)
>>> model.evaluate(X_test, y_test
>>> y_pred = model.predict(X_test)
컨퓨전 매트릭스 확인
어떤 것을 컴퓨터가 많이 헷갈려 하는지 파악한다.
from sklearn.metrics import confusion_matrix
>>> y_pred = model.predict(X_test)
# numpy의 argmax() 함수를 이용하면 가장 큰 값이 들어있는 곳의 인덱스를 얻을 수 있다.
>>> y_pred = y_pred.argmax(axis=1)
>>> confusion_matrix(y_test, y_pred)
'인공지능 > Deep Learning' 카테고리의 다른 글
| [Deep Learning] CNN Convloution (0) | 2024.04.18 |
|---|---|
| [Deep Learning] TensorFlow EarlyStopping (0) | 2024.04.18 |
| [Deep Learning] epochs history 차트 시각화 (0) | 2024.04.17 |
| [Deep Learning] DNN TensorFlow Regression 수치 예측 문제 모델링 (0) | 2024.04.17 |
| [Deep Learning] TensorFlow GridSearch (0) | 2024.04.17 |